case study
Atlas Bridge
Built a bi-directional ETL bridge that keeps the legacy Atlas Phoenix monolith and the modern Atlas micro-services platform consistent during a long deprecation period.
Overview & Problem
The Atlas ecosystem consists of a legacy Phoenix monolith and the new full-stack JavaScript Atlas Platform built as micro-services.
Both systems are temporarily running in parallel in production until we deprecate the legacy monolith. Without a sync mechanism, data between the systems would quickly become inconsistent, leading to operational issues and increased maintenance overhead.
Solution
I built Atlas Bridge, an ETL system in Node.js, using Koa, that keeps both systems in sync automatically. It handles bi-directional data flow, ensures transactional integrity, and leverages Datadog observability for production reliability.
Atlas Bridge runs on a scheduled CronJob that checks for data changes
every minute using the
updated_at
field in both databases to determine the most recent change.
System Architecture
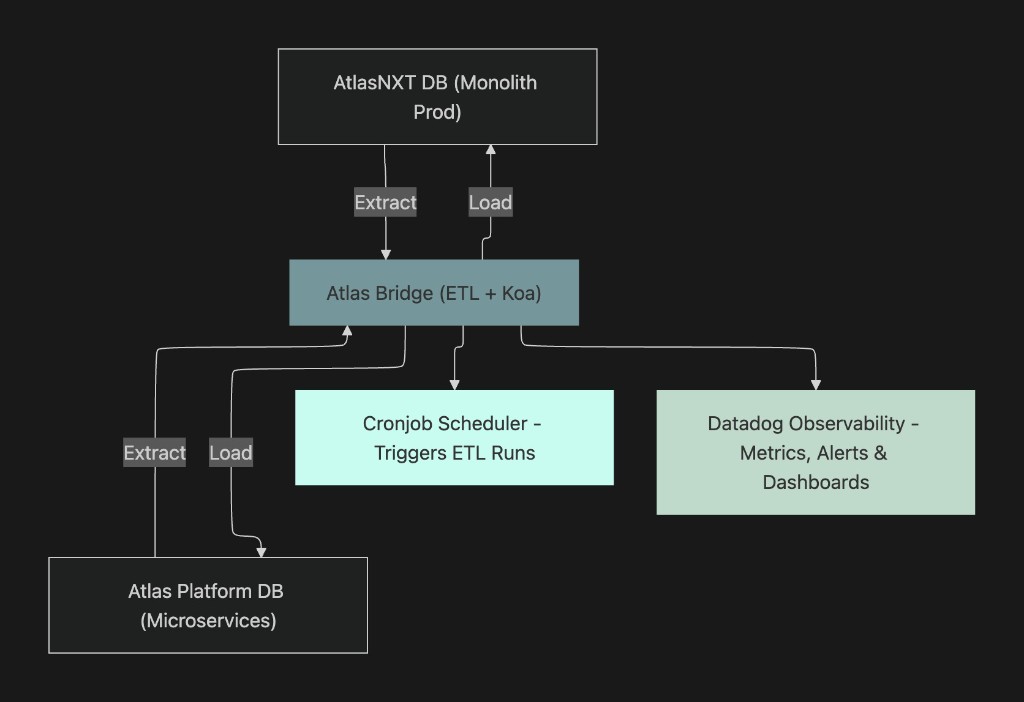
Highlights
- Atlas Bridge sits at the centre, handling ETL, data transformation, and conflict resolution.
- Cronjobs trigger scheduled syncs, ensuring up-to-date consistency.
- Datadog observability provides metrics, alerting, and dashboards for system health and reliability.
Technical Challenges & Solutions
- Bi-directional sync: prevented overwriting newer updates via timestamp-based conflict resolution.
- Schema differences: transformation layer reconciles legacy Atlas fields with new micro-service schemas.
- Transactional safety: database transactions ensure atomic updates and prevent partial writes.
- Production reliability: observability in Datadog ensures failures are detected, tracked, and alerted immediately.
Code Snippets
// Paginate tenant Postgres (Knex) with offset/limit. Process each page in parallel,
// recurse until a short page. Stages ordered: users/staff → teams/categories → geofences/members → reconcile deletes.
// e.g. Promise.all([ batchProcess(users...), batchProcess(staff...), ... ])
async function batchProcess<R, P>(
retrieve: (offset: number, limit: number) => Promise<R[]>,
processor: (row: R) => Promise<P>,
offset = 0,
limit = 100,
): Promise<P[]> {
const records = await retrieve(offset, limit);
const processed = await Promise.all(records.map(processor));
if (records.length === limit) {
return [...processed, ...(await batchProcess(retrieve, processor, offset + limit, limit))];
}
return processed;
}Batched, ordered ETL from tenant DB into platform services with explicit reconciliation passes.
// Per-tenant CronJob: labels for org/tenant, schedule from config, tight job history,
// single completion. Container runs the compiled sync entrypoint (not the HTTP server).
const cronJob = {
kind: 'CronJob',
metadata: { labels: { /* org id, tenant name, component: sync-job */ } },
spec: {
schedule: config.cron.schedule,
failedJobsHistoryLimit: 0,
successfulJobsHistoryLimit: 1,
startingDeadlineSeconds: 120,
jobTemplate: {
spec: {
completions: 1,
template: {
spec: {
containers: [{
name: 'sync',
image: config.job.image,
command: ['/nodejs/bin/node', '--require=dd-trace/init', 'src/job.js'],
env: [ /* TENANT_*, DATABASE_*, service hostnames, … */ ],
}],
restartPolicy: 'OnFailure',
},
},
},
},
},
};Kubernetes CronJobs created/updated from Node; sync workload runs under dd-trace.
Impact & Metrics
- Syncs thousands of records per run with zero data inconsistencies.
- Reduces manual reconciliation across production systems, saving hundreds of man-hours.
- Minimises urgency to remove legacy system, ensuring that we can continue to deliver new features and de-prioritise rebuilding existing services.
- Datadog dashboards provide real-time monitoring of ETL health, sync latency, and error rates.
Skills Demonstrated
- Backend system design with Node.js and Koa.
- ETL pipeline architecture.
- Database design, transactions, and indexing.
- Scheduling, automation, and failure recovery.
- Observability and production monitoring using Datadog.
- Bi-directional data synchronisation and conflict resolution.